How Reasoning Models Work in 2026: The Training, Inference, and Verification Stack
Reasoning models are everywhere in AI marketing right now. The product story sounds magical. The engineering story is more useful: they are mostly standard LLMs wrapped in better training loops, stronger verification, and more deliberate compute at inference.
The short version:
- They are usually standard LLM architectures.
- They are trained with stronger post-training loops (often RL + verification).
- They spend more compute at inference time on hard problems.
- They only become production-safe when wrapped in external verification and routing.
This post synthesizes four references and turns them into one practical takeaway:
- the critical framing from the arXiv paper (How) Do Reasoning Models Reason?,
- Sebastian Raschka's practical taxonomy of approaches,
- a build-from-scratch pipeline explanation,
- and OpenAI's official API guidance for reasoning models.
If you are shipping AI systems, the key point is simple: reasoning quality is mostly a systems problem, not just a model problem.
What Is a Reasoning Model, Exactly?
A useful operational definition is:
- A reasoning model is an LLM tuned to solve complex tasks through intermediate derivation steps and/or additional test-time search.
That matches Sebastian's framing: reasoning models are a specialization of LLMs for multi-step tasks (math, coding, logic, planning), not a universal replacement for every prompt type.
In practice, two separate mechanisms are often conflated:
- Inference-time scaling: spend more compute per query (longer traces, multiple candidates, selection).
- Post-training specialization: train the model to produce better intermediate trajectories and final answers.
The arXiv paper is especially useful here because it separates these two mechanisms clearly and pushes back on the myth that long traces automatically mean real reasoning.
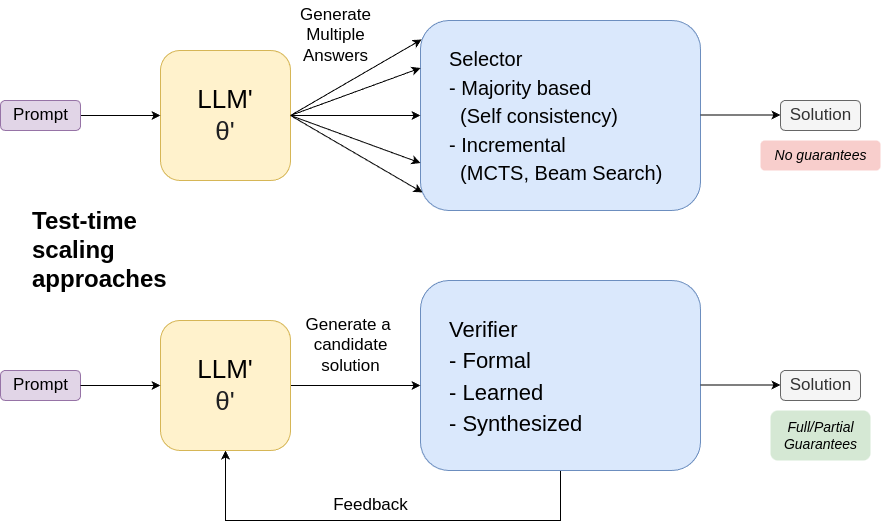
Mechanism 1: Inference-Time Scaling (Generate, Then Select/Test)
For hard tasks, one-shot generation is usually brittle. Reasoning systems often improve reliability by generating multiple candidate paths and then selecting or verifying.
Common patterns:
- self-consistency (majority vote across samples),
- search-based decoding,
- generate-test loops with formal or learned verifiers,
- feedback loops that regenerate after verifier critique.
This is powerful because it can raise accuracy quickly without retraining the base model. The trade-offs are real:
- higher token and latency cost,
- weaker streaming behavior,
- no inherent correctness guarantees unless the verifier itself is sound.
Mechanism 2: Post-Training on Derivational Traces
Reasoning gains also come from training on intermediate trajectories (sometimes called traces or CoT-style derivations), then reinforcing outputs that pass checks.
, CC BY 4.0, via arXiv 2504.09762v1")
Think of modern recipes as a spectrum:
- SFT on worked solutions and traces.
- RL with verifiable rewards (math checks, code tests, strict format checks).
- SFT + RL multi-stage pipelines (the DeepSeek R1 style blueprint).
- Distillation into smaller models.
Raschka's four-approach framing is practical:
- inference-time scaling,
- pure RL,
- SFT + RL,
- pure SFT/distillation from stronger reasoners.
For most teams, distillation and targeted SFT remain the most financially realistic path.
The Verifier Is the Real Core
The strongest insight across sources is this: verifier quality determines how much of your "reasoning" is real versus stylistic noise.
The arXiv paper argues that many gains are better explained as improved generate-test pipelines than as transparent windows into machine thought. That is a healthy, engineering-first framing.
Why verifier design is hard:
- Exact matching can reject equivalent correct answers.
- Weak verifiers are gameable (reward hacking).
- LLM-as-judge verification can drift or hallucinate.
- Open-ended domains are expensive to score reliably.
Practical implication: if your application is high stakes, treat the model as a candidate generator and keep external checks in the loop.
Are Reasoning Traces Actually "Reasoning"?
This is the most controversial part.
The arXiv paper explicitly warns against anthropomorphizing intermediate tokens. A trace can look persuasive and still be invalid or decoupled from the real cause of correctness.
, CC BY 4.0, via arXiv 2504.09762v1")
My take is blunt: in product systems, optimize for verified outcomes and calibrated confidence, not polished-looking reasoning prose.
What OpenAI's API Guidance Means in Practice
OpenAI's reasoning guide makes a few important production points:
reasoning.effortis a cost-latency-quality knob (nonetoxhigh, model-dependent).- Reasoning tokens consume context and are billed.
max_output_tokenscan fail mid-reasoning withincompleteresponses.- You should reserve enough token budget (OpenAI suggests starting with a large buffer while profiling).
- For tool loops, preserve reasoning-related items across turns in Responses API flows.
In other words, model quality is not enough. You need token budgeting, response-state handling, and eval-driven effort policies.
Cost Reality: Better Accuracy, Non-Trivial Overhead
Reasoning models often outperform standard LLMs on hard verifiable tasks, but not for free.
The arXiv authors highlight cost and robustness caveats; OpenAI docs highlight the practical token mechanics; and real-world teams repeatedly discover the same outcome:
- better hard-task solve rates,
- but higher per-request cost,
- more variance in latency,
- occasional overthinking on simple tasks.
If every request gets high-effort reasoning, you can burn budget fast with little user-visible gain on easy prompts.
A Production Architecture That Usually Wins
For most teams, this pattern is stronger than a single always-reasoning model:
- Route: classify query difficulty/risk.
- Budget: assign low/medium/high effort dynamically.
- Generate: use reasoner only where expected value is positive.
- Verify: run domain checks before accepting outputs.
- Escalate: retry with higher effort or human handoff on failures.
This is aligned with what I wrote earlier on confidence thresholds and token economics. It also beats the naive "use the strongest model always" strategy in real systems.
Benchmarks: Useful, But Don't Mistake for Robustness
Recent models have made real gains on difficult benchmarks, but benchmark wins alone are insufficient for production trust.
The PlanBench comparisons in the arXiv discussion illustrate both progress and brittleness.
, CC BY 4.0, via arXiv 2504.09762v1")
Takeaway:
- treat benchmark gains as capability signals,
- then validate with task-specific evals, failure analysis, and adversarial prompts.
Practical Build Recipe (If You Want to Train Your Own)
If you are experimenting with your own reasoner, use this recipe:
- Start with a strong base model for your domain.
- Curate high-quality solved examples with intermediate structure.
- Add verifiable tasks early (math, code tests, structural validators).
- Fine-tune for format and task adherence.
- Add RL or preference optimization only after evaluator quality is stable.
- Distill into smaller serving models for cost-sensitive deployment.
- Keep a strict eval harness and run regression tests every checkpoint.
Low-budget teams should pay special attention to distillation-oriented approaches and targeted SFT instead of betting everything on expensive RL.
Final Takeaway
Reasoning models are not magic, and they are not fake hype either. They are an important systems evolution:
- more deliberate compute at inference,
- stronger post-training loops,
- and a bigger dependency on verifier quality.
If you remember one sentence, make it this:
Reasoning performance scales when you combine model capability with reliable verification and adaptive compute policy.
That is the gap between a demo and a production system.
FAQ
Are reasoning models always better than standard LLMs?
No. They usually help on complex, multi-step, verifiable tasks. For simple extraction, classification, and short factual responses, they are often slower and more expensive without quality gain.
Should I expose chain-of-thought to users?
In most products, no. Keep user-facing outputs concise and focus on verifiable final answers. Exposed traces can create false confidence if users interpret style as correctness.
Is pure RL enough to build a strong reasoner?
Pure RL can produce emergent reasoning behavior, but multi-stage pipelines (SFT + RL + distillation) are still more reliable in practice.
What is the best first step for a startup team?
Implement routing + verifier + eval harness first. Then tune reasoning effort and only later consider custom post-training.
Sources
- Kambhampati, Stechly, Valmeekam. (How) Do Reasoning Models Reason?.
- Sebastian Raschka. Understanding Reasoning LLMs.
- Micheal Lanham. How Reasoning Models Actually Work: Building One From Scratch.
- OpenAI Developers. Reasoning models guide.
Standard LLMs vs Reasoning Models
A standard instruction model is optimized to produce a good answer quickly in one pass. It may produce a short explanation, but it is still mostly a direct mapping from prompt to response.
A reasoning model is optimized to do more work before committing to a final answer. That work can include:
- decomposing a problem into subproblems,
- trying multiple candidate paths,
- checking intermediate steps,
- revising earlier steps when contradictions appear.
The output you see is usually a compressed summary. The model may internally produce much longer reasoning text or multiple trajectories that are filtered before the final answer.
Conceptually:
- Standard model: answer-first behavior.
- Reasoning model: search-and-verify behavior.
That is why the same base model family can feel dramatically stronger on coding, math, and formal tasks once reasoning training is added.
The Core Training Shift: RL with Verifiable Signals
The most practical way to teach reasoning behavior is reinforcement learning with reliable rewards.
Why this matters:
- If reward quality is noisy, the model learns shortcuts.
- If reward quality is reliable, the model learns strategy.
For reasoning tasks, the best rewards are often verifiable:
- math: exact final answer checks,
- code: test-suite execution,
- formatting: hard structural constraints,
- constrained tasks: rule-based validators.
A simple mental model for training:
- Sample a reasoning trajectory.
- Score it using deterministic checks (or a verifier).
- Update policy to increase trajectories that pass.
- Repeat at scale.
You do not hard-code "decompose the task" into the model. You define incentives where decomposition and self-correction produce higher reward. The behavior then emerges from optimization.
Why Verification Is the Hard Part
People often focus on the model. In practice, verification is the system.
Even in math, exact string matching is fragile. Equivalent forms can fail naive checks. In code, test coverage can miss brittle but incorrect solutions. In open-ended tasks, deterministic verification barely exists.
So teams combine methods:
- deterministic checks where possible,
- programmatic validators for structure and constraints,
- model-based verifiers for fuzzy equivalence,
- human preference signals where automatic checks break down.
This is where many reasoning pipelines fail. If your verifier can be gamed, RL will find the exploit. If your verifier is too strict, learning collapses. If it is too loose, quality plateaus.
Reasoning quality is therefore not just a model problem. It is a reward-design and evaluator-engineering problem.
Inference-Time Scaling: Paying Compute Where It Matters
Reasoning models introduced a useful product lever: dynamic compute at inference.
Instead of paying a fixed cost for every request, you scale effort with task difficulty. Typical controls include:
- longer reasoning traces,
- multiple sampled trajectories,
- majority vote or best-of-N selection,
- critique and revision loops,
- external tool checks between iterations.
This introduces an explicit quality-cost frontier:
- low effort: cheaper, faster, lower reliability on hard tasks,
- medium effort: balanced,
- high effort: expensive, slower, best on verifiable tasks.
From an infra perspective, this looks like a new scheduler problem: route simple prompts to low effort, escalate ambiguous prompts to high effort, and verify before returning high-confidence outputs.
If you liked my cost piece, this is the same principle from a different angle: we are shifting where tokens and compute are spent to maximize outcome quality per dollar. See Token Economics: Why Your Agent Architecture Is Costing 10x More Than It Should.
Reasoning Traces Are Not Just "Long Chain-of-Thought"
A lot of discussion reduces reasoning models to "just longer chain-of-thought." That is incomplete.
Length alone does not create reasoning. You can generate a long but wrong trace.
What matters is the loop:
- generate candidate reasoning,
- evaluate candidate quality,
- reinforce better trajectories,
- repeat with stronger data and better verifiers.
Long traces are the substrate. Training objective and selection pressure are the engine.
Another important distinction: many providers do not expose raw traces to end users. They may provide summaries for safety, UX, or policy reasons. This means product teams should evaluate outcomes and trace-derived diagnostics, not assume full transparent reasoning logs will always be available.
Open vs Closed Reasoning Models
Closed model providers demonstrated early performance jumps, but open models have made the mechanisms more legible.
Open efforts showed a few practical truths:
- Pure RL can surface reasoning behavior.
- SFT warm starts still stabilize training and improve usability.
- Distillation from strong reasoners into smaller dense models works surprisingly well.
Distillation matters a lot for startups. Most teams cannot train frontier reasoners from scratch, but many teams can fine-tune and serve distilled models with better cost-performance for specific domains.
This is similar to what happened in earlier open model waves: once the recipe becomes partially visible, ecosystem iteration accelerates.
Production Playbook: How to Use Reasoning Models Safely
If you run reasoning models in production, do not treat them as a drop-in chat replacement. Build a policy around them.
1) Route by task type
Use reasoners for tasks where correctness is verifiable or expensive to get wrong:
- code generation with tests,
- math/finance calculations,
- structured planning with constraints,
- data transformation pipelines.
Use standard models for low-risk conversational UX where latency and cost dominate.
2) Add confidence and handoff thresholds
Not every prompt should trigger maximum reasoning effort. Define thresholds for:
- when to escalate effort,
- when to ask clarifying questions,
- when to hand off to a human.
I covered this pattern in When Agents Should Not Decide: Building Confidence Thresholds for Human Handoff.
3) Monitor reasoning-specific metrics
Track metrics beyond simple response latency:
- verifier pass rate,
- agreement rate across samples,
- revision loop depth,
- contradiction rate in self-checks,
- cost per successful verified answer.
These metrics reveal whether quality improvements are real or just token inflation.
4) Defend against overthinking
More thinking is not always better. Overthinking can increase latency and even introduce spurious errors on easy tasks.
Use adaptive budgets:
- start with low effort,
- escalate only when uncertainty or verification failure is detected,
- cap loop depth to avoid runaway costs.
Common Failure Modes
Reasoning models are powerful, but current systems fail in predictable ways:
- Verifier mismatch: training reward does not reflect real-world correctness.
- Prompt sensitivity: small prompt changes produce large variance.
- Instruction drift: strong reasoning can still miss strict formatting requirements.
- Latency spikes: variable reasoning depth creates tail latency issues.
- Reward hacking: model learns to satisfy proxy checks without solving the true task.
Treat these as engineering constraints, not surprises.
A Practical Mental Model
Use this mental model when designing with reasoners:
- Pretraining gives broad capabilities.
- Post-training gives usable behavior.
- Reasoning RL gives strategic search behavior.
- Verification gives direction to that search.
- Inference-time compute lets you buy extra reliability when needed.
Reasoning models are not a different species of model. They are LLM systems with stronger optimization around deliberate problem solving.
Where This Is Going Next
The next wave will likely converge on hybrid systems:
- compact models for fast drafting,
- reasoners for hard checkpoints,
- verifiers and tools for external grounding,
- adaptive routers for cost and latency control.
In other words: not one mega-model doing everything, but a coordinated stack with explicit quality gates.
That is also why agent architecture matters more than model leaderboard rankings. A weaker model with better verification and routing can outperform a stronger model in real deployment.
Final Takeaway
Reasoning models work because they turn "thinking" into an optimizable process:
- reward the right behaviors during training,
- verify aggressively,
- spend inference compute selectively,
- measure outcomes with the right metrics.
If you apply these principles, you do not just get better benchmark scores. You get systems that fail less often when stakes are real.
And that is the only metric that matters in production.